folder_open ~/Benchmarks/Wiki Live Challenge
Wiki Live Challenge: Challenging Deep Research Agents with Expert-Level Wikipedia Articles
1University of Science and Technology of China 2Metastone Technology, Beijing, China
{wsh2000, benfeng, zlczlc}@mail.ustc.edu.cn
*Work done during internship at Metastone †Project lead §Corresponding author
Abstract
Deep Research Agents (DRAs) have demonstrated remarkable capabilities in autonomous information retrieval and report generation, showing great potential to assist humans in complex research tasks. Current evaluation frameworks primarily rely on LLM-generated references or LLM-derived evaluation dimensions. While these approaches offer scalability, they often lack the reliability of expert-verified content and struggle to provide objective, fine-grained assessments of critical dimensions.
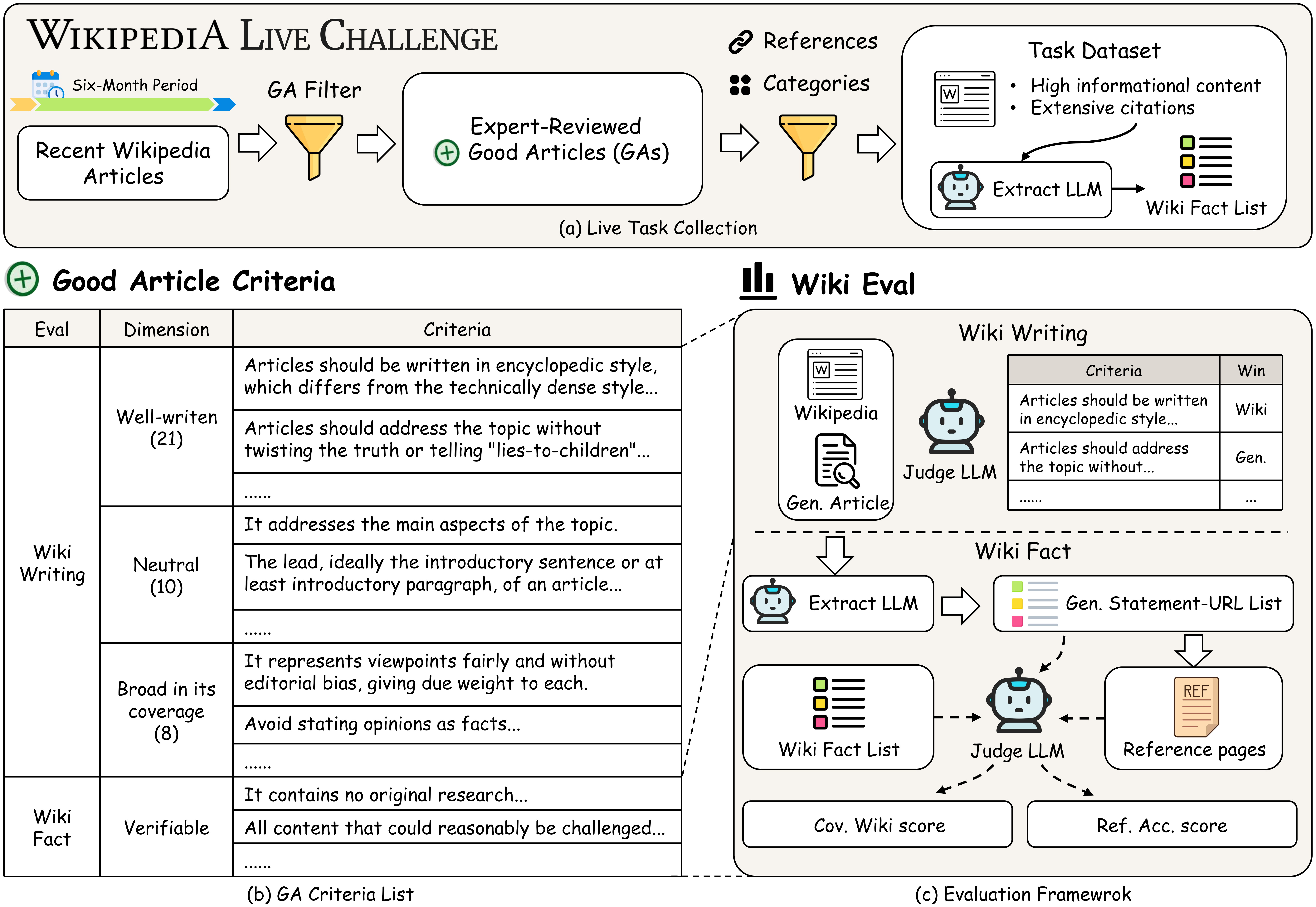
We introduce Wiki Live Challenge (WLC), a live benchmark that leverages the newest Wikipedia Good Articles (GAs) as expert-level references. Wikipedia's strict standards for neutrality, comprehensiveness, and verifiability serve as a great challenge for DRAs, with GAs representing the pinnacle of which. We curate a dataset of 100 recent Good Articles and propose Wiki Eval, a comprehensive evaluation framework comprising a fine-grained evaluation method with 39 criteria for writing quality and rigorous metrics for factual verifiability.
analytics Benchmark Statistics sync Live
Good Articles
Wikipedia expert-reviewed
Evaluation Criteria
Fine-grained & GA-aligned
Categories
Comprehensive coverage
Eval Dimensions
Writing & Factuality
2025 Collection
Continuously updating
info This is a live benchmark. We continuously collect the newest Wikipedia Good Articles to avoid data contamination and ensure content postdates the knowledge cutoff of current models.
schema Wiki Eval Framework
Our evaluation framework is grounded in Wikipedia Good Article criteria, comprising two key dimensions:
Wiki Writing
Fine-grained writing evaluation based on Wikipedia GA criteria with 39 distinct criteria.
- Well-written: Clear, concise, encyclopedic style
- Neutral: Fair viewpoints without editorial bias
- Broad Coverage: Addresses main aspects comprehensively
Wiki Fact
Factual accuracy evaluation measuring coverage and verifiability.
- Cov. Wiki: Coverage of Wikipedia facts
- Ref. Acc.: Statements supported by cited references
- Strict verifiability against expert sources
checklist Writing Criteria Overview
Well-written
Lead section, clarity, style
Neutral
Viewpoints, due weight
Broad Coverage
Scope, focus, completeness
insights Key Findings
- arrow_right Significant Gap: Even the best-performing agent (Gemini-3-pro Deep Research) achieves only 58.33% overall writing score, indicating substantial room for improvement compared to human expert-level Wikipedia articles.
- arrow_right Low Fact Coverage: All DRA systems perform poorly in covering Wikipedia facts, with the best achieving only 30.76% coverage, showing current models are far from expert-level information gathering.
- arrow_right Domain Variation: Performance varies significantly across categories—History and Mathematics are most challenging (<20% win rate), while Natural Sciences and Philosophy exceed 40%.
- arrow_right Open-Source Gap: Fully open-source DRA frameworks lag significantly behind proprietary models, with Deep Researcher scoring only 2.28%.
Citation
@misc{wang2026wikilivechallengechallenging,
title={Wiki Live Challenge: Challenging Deep Research Agents with Expert-Level Wikipedia Articles},
author={Shaohan Wang and Benfeng Xu and Licheng Zhang and Mingxuan Du and Chiwei Zhu and Xiaorui Wang and Zhendong Mao and Yongdong Zhang},
year={2026},
eprint={2602.01590},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2602.01590},
}
Leaderboard Live
Current Dataset Version v1.0
100 Wikipedia Good Articles from March – November 2025
Last updated: Jan 2026
schedule More data coming soon
info This is a live benchmark. We continuously collect the newest Wikipedia Good Articles to avoid data contamination and ensure content postdates the knowledge cutoff of current models. Future updates will include more recent articles.
| # | Model | Type | Overall | Well-writ. | Neutral | Broad | Cov. Wiki | Ref. Acc. |
|---|---|---|---|---|---|---|---|---|
| 1 |
Gemini-3-pro Deep Research
Google, 2025
|
Proprietary | 58.33 | 60.81 | 46.10 | 67.12 | 28.83 | 66.98 |
| 2 |
Langchain (GPT-5)
Open-source + GPT-5
|
Open-Source | 53.62 | 50.95 | 54.20 | 59.88 | 20.96 | 67.60 |
| 3 |
Gemini-2.5-pro Deep Research
Google, 2025
|
Proprietary | 35.18 | 30.10 | 26.10 | 59.88 | 30.76 | 41.68 |
| 4 |
OpenAI o3 Deep Research
OpenAI, 2025
|
Proprietary | 31.08 | 28.43 | 24.90 | 45.75 | 25.12 | 57.44 |
| 5 |
Grok Deep Search
xAI
|
Proprietary | 28.38 | 27.52 | 24.30 | 35.75 | 20.73 | 60.63 |
| 6 |
Perplexity Deep Research
Perplexity AI, 2025
|
Proprietary | 27.38 | 26.79 | 20.40 | 37.63 | 29.21 | 28.27 |
| 7 |
Qwen-3-max Deep Research
Alibaba Qwen, 2025
|
Proprietary | 25.15 | 18.29 | 27.70 | 40.00 | 22.22 | 61.44 |
| 8 |
Langchain (GPT-4.1)
Open-source + GPT-4.1
|
Open-Source | 20.67 | 18.76 | 19.40 | 27.25 | 7.08 | 7.34 |
| 9 |
Doubao Deep Research
ByteDance
|
Proprietary | 19.13 | 16.00 | 16.10 | 31.13 | 22.97 | 37.05 |
| 10 |
Tongyi Deep Research
Alibaba Tongyi, 2025
|
Open-Source | 15.05 | 10.90 | 11.60 | 30.25 | 22.73 | -- |
| 11 |
Deep Researcher
Open-source
|
Open-Source | 2.28 | 1.90 | 1.90 | 3.75 | 5.62 | -- |
* Wiki Writing scores are win rates (%) against Wikipedia Good Articles. Cov. Wiki and Ref. Acc. are factual metrics (%). "--" indicates unavailable due to citation formatting issues.
info Scoring Metrics
Overall win rate against Wikipedia across 39 GA-based criteria (Well-written, Neutral, Broad)
Factual coverage against extracted Wikipedia fact list
Proportion of statements supported by their cited references
Methodology Notes
- Wiki Writing: Computed by aggregating wins over 39 Wikipedia GA-based criteria across three dimensions: Well-written, Neutral, and Broad in Coverage.
- Cov. Wiki (Coverage): Measures factual coverage against the extracted Wikipedia fact list using retrieval and fact-checking.
- Ref. Acc. (Reference Accuracy): Measures the proportion of cited statements that are supported by their referenced webpages.
- Judge Model: Gemini-2.5-pro is used for Wiki Writing evaluation (83.59% agreement with human annotations).
add_circle Join the Leaderboard
If you would like to add your model to the leaderboard, please contact us at wsh2000@mail.ustc.edu.cn.