The Problem with Current RAG Systems
Frontier language models have demonstrated remarkable reasoning and long-horizon tool-use capabilities. However, existing RAG systems fail to leverage these advancements. Traditional approaches — including Naive RAG, Graph RAG, and Workflow RAG — do not fully exploit the autonomous decision-making potential of modern agentic models.
These systems either retrieve passages in a single shot and concatenate them into the model's input, or predefine a rigid workflow that the model must follow step-by-step. As a result, they cannot scale with improvements in model reasoning and tool-use abilities.
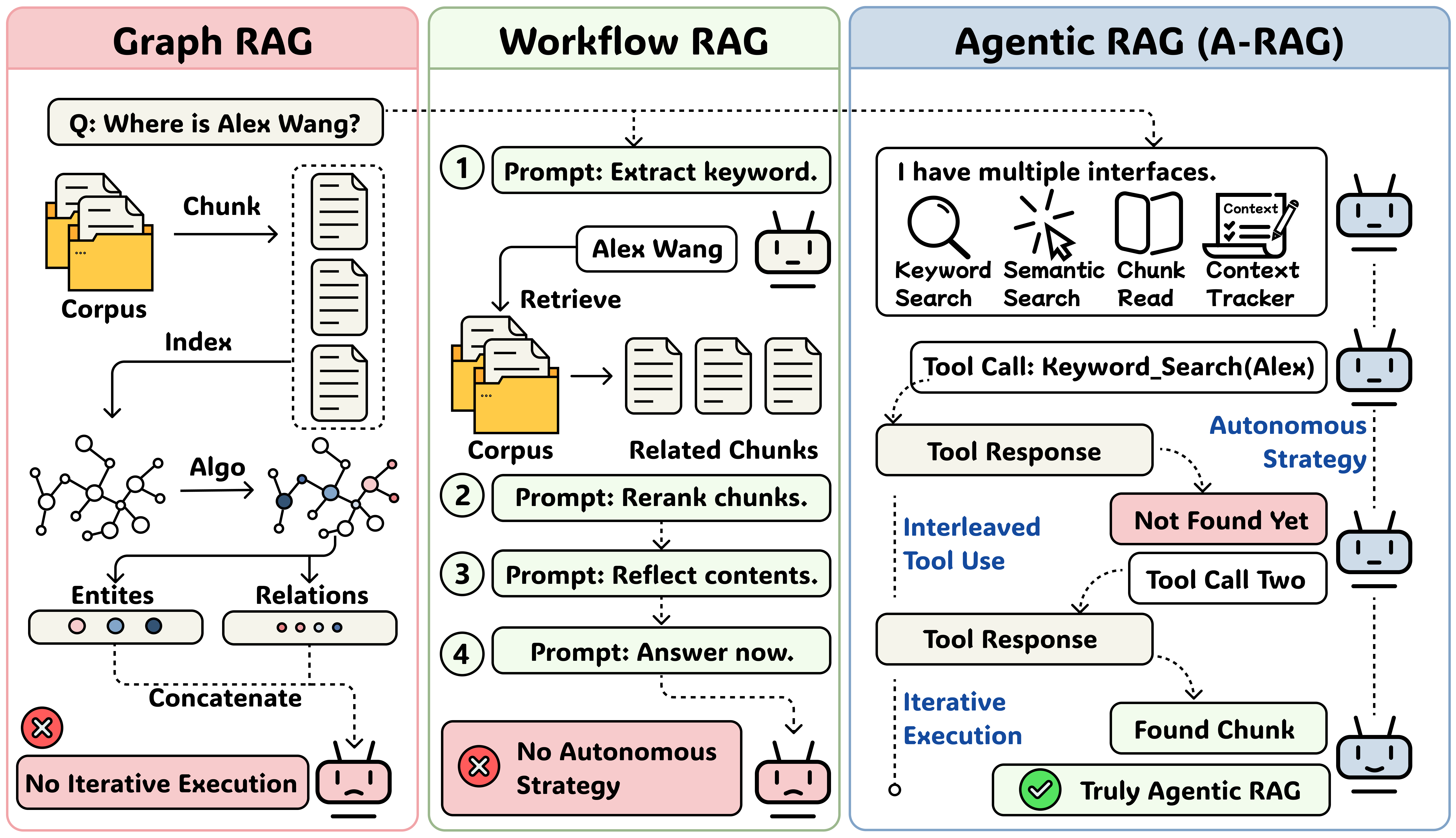
Figure 1: Evolution of RAG paradigms — from Naive RAG to Workflow RAG, and finally to Agentic RAG.
Our Solution: A-RAG
We introduce A-RAG (Agentic Retrieval-Augmented Generation), a framework that exposes hierarchical retrieval interfaces directly to the model. Instead of constraining the model to predefined workflows, A-RAG lets the agent autonomously decide:
- When to retrieve — the agent determines the optimal timing for retrieval based on its current context
- What to retrieve — the agent formulates queries adaptively based on information gaps
- How to retrieve — the agent selects from multiple retrieval tools at different granularities
A-RAG provides three core retrieval tools: keyword_search for exact lexical matching, semantic_search for dense retrieval, and chunk_read for accessing full document chunks. The agent can freely combine these tools in any order, adapting its strategy based on intermediate results.
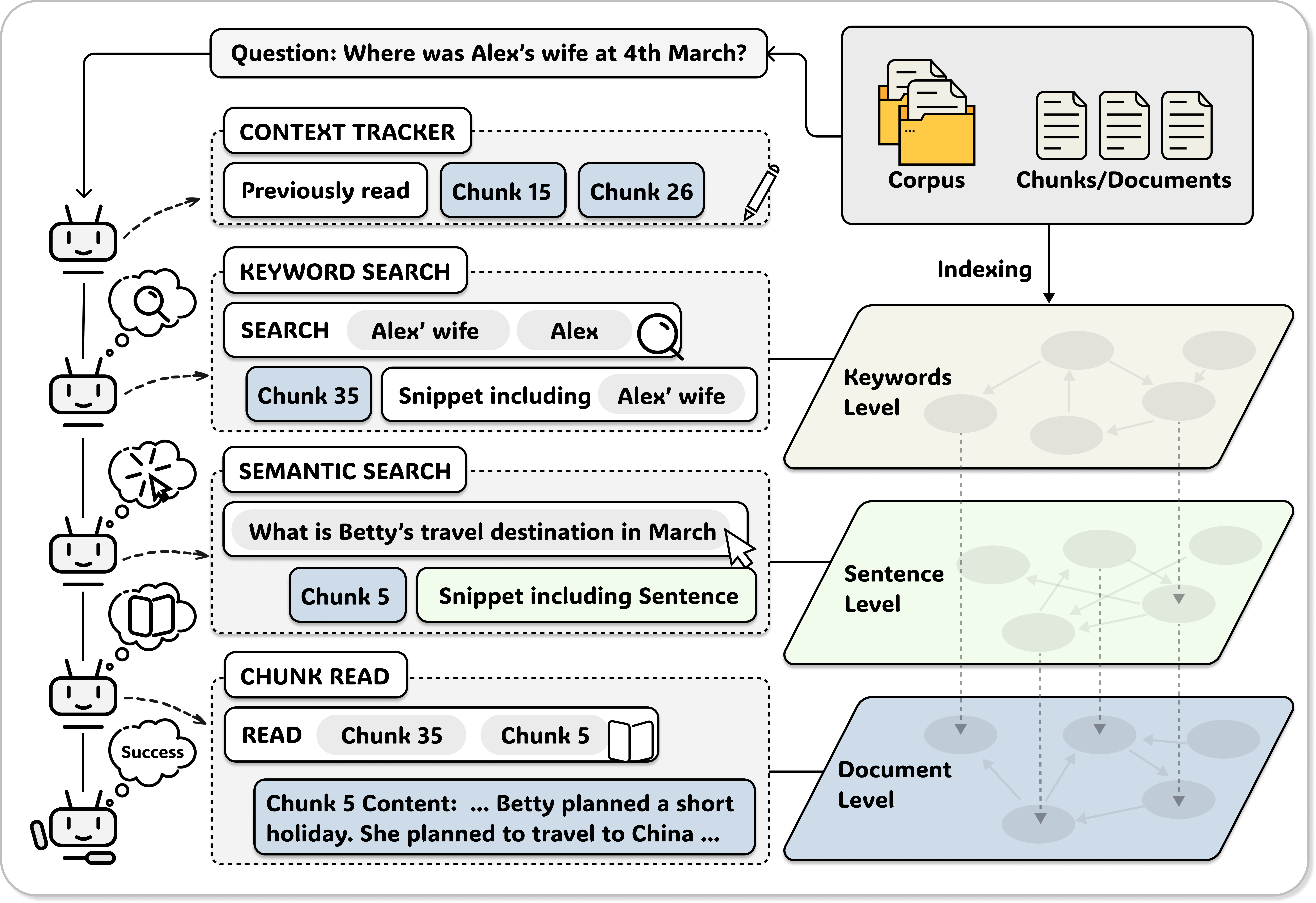
Figure 2: A-RAG framework — the agent autonomously orchestrates retrieval through hierarchical interfaces.
Experimental Results
We evaluate A-RAG against strong baselines including GraphRAG, HippoRAG2, LinearRAG, FaithfulRAG, MA-RAG, and RAGentA across multiple benchmarks covering multi-hop QA (MuSiQue, HotpotQA, 2WikiMultiHop), domain-specific QA (Medical), and long-context understanding (Novel). A-RAG consistently achieves state-of-the-art performance, demonstrating the benefits of agentic autonomy.
| Method | MuSiQue | HotpotQA | 2Wiki | Medical | Novel | |||
|---|---|---|---|---|---|---|---|---|
| LLM | Cont | LLM | Cont | LLM | Cont | LLM | LLM | |
| GPT-4o-mini | ||||||||
| Vanilla Baselines | ||||||||
| Direct Answer | 18.3 | 13.9 | 45.4 | 40.7 | 30.3 | 49.7 | 68.6 | 45.3 |
| Naive RAG | 38.6 | 36.1 | 74.5 | 72.9 | 42.6 | 59.0 | 75.3 | 68.5 |
| Graph-RAG and Workflow RAG | ||||||||
| GraphRAG | 26.4 | 20.8 | 33.2 | 33.3 | 18.4 | 47.2 | 51.3 | 28.8 |
| HippoRAG2 | 40.6 | 38.4 | 80.7 | 69.7 | 64.7 | 68.5 | 72.0 | 70.1 |
| LinearRAG | 34.8 | 26.3 | 72.0 | 60.5 | 62.9 | 62.3 | 53.1 | 45.4 |
| FaithfulRAG | 28.8 | 22.6 | 60.5 | 52.5 | 38.8 | 38.1 | 42.5 | 33.3 |
| MA-RAG | 34.1 | 27.4 | 60.6 | 54.4 | 51.0 | 53.4 | 62.3 | 44.5 |
| RAGentA | 32.2 | 29.9 | 63.0 | 62.4 | 27.7 | 50.3 | 67.7 | 61.3 |
| A-RAG (Ours) | ||||||||
| A-RAG (Naive) | 43.8 | 38.5 | 76.6 | 70.7 | 52.3 | 62.4 | 79.0 | 70.0 |
| A-RAG (Full) | 46.1 | 39.6 | 77.1 | 74.0 | 60.2 | 63.7 | 79.4 | 72.7 |
| GPT-5-mini | ||||||||
| Vanilla Baselines | ||||||||
| Direct Answer | 35.8 | 26.5 | 63.6 | 53.5 | 51.3 | 54.0 | 90.5 | 45.1 |
| Naive RAG | 52.8 | 48.7 | 81.2 | 79.5 | 50.2 | 66.5 | 86.1 | 70.6 |
| Graph-RAG and Workflow RAG | ||||||||
| GraphRAG | 48.3 | 39.1 | 82.5 | 74.9 | 66.5 | 70.7 | 87.3 | 77.1 |
| HippoRAG2 | 61.7 | 52.5 | 84.8 | 75.0 | 82.0 | 79.7 | 78.2 | 54.3 |
| LinearRAG | 62.4 | 51.8 | 86.2 | 77.6 | 87.2 | 84.8 | 79.2 | 54.7 |
| FaithfulRAG | 52.9 | 52.8 | 76.9 | 75.3 | 51.8 | 56.6 | 75.4 | 60.7 |
| MA-RAG | 40.0 | 31.6 | 67.1 | 57.9 | 54.7 | 54.3 | 68.3 | 45.1 |
| RAGentA | 38.3 | 37.4 | 61.2 | 65.0 | 24.0 | 53.5 | 73.7 | 60.2 |
| A-RAG (Ours) | ||||||||
| A-RAG (Naive) | 66.2 | 59.7 | 90.8 | 85.3 | 70.6 | 76.9 | 92.7 | 80.4 |
| A-RAG (Full) | 74.1 | 65.3 | 94.5 | 88.0 | 89.7 | 88.9 | 93.1 | 85.3 |
Table: Results (%) on benchmark datasets. LLM = LLM-Evaluation Accuracy, Cont = Contain-Match Accuracy. Bold = best, underline = second best.
Key Takeaway
A-RAG achieves state-of-the-art performance across all benchmarks with GPT-5-mini, reaching 94.5% on HotpotQA and 89.7% on 2WikiMultiHop. More importantly, A-RAG's performance scales with model capability — the gap between A-RAG and baselines widens as the backbone model improves, validating our hypothesis that agentic systems can better leverage advances in model reasoning.
Citation
@article{du2026arag,
title={A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces},
author={Du, Mingxuan and Xu, Benfeng and Zhu, Chiwei and Wang, Shaohan and Wang, Pengyu and Wang, Xiaorui and Mao, Zhendong},
journal={arXiv preprint arXiv:2602.03442},
year={2026}
}